Cos'è la RAG (Retrieval-Augmented Generation)?
Come funziona la RAG: la tecnologia che migliora i Large Language Models con informazioni aggiornate e contestuali

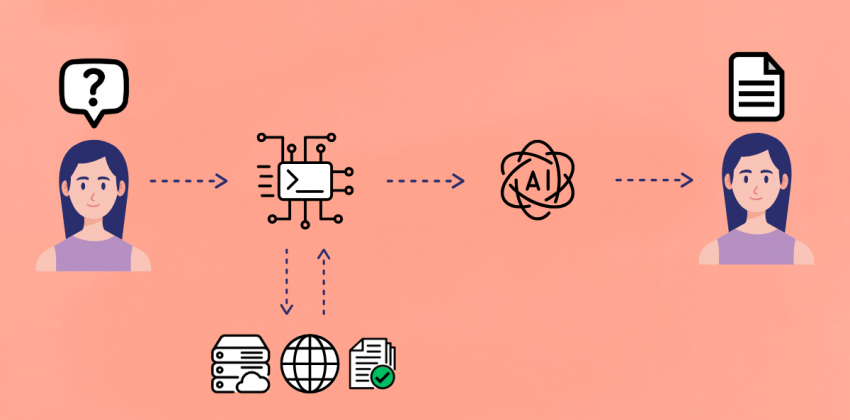
Nel panorama in continua e rapida evoluzione dell’Intelligenza Artificiale, i Large Language Models (LLM) hanno dimostrato capacità sorprendenti nella generazione di testo coerente e contestualmente rilevante. Tuttavia, anche i modelli più avanzati possono incappare in problemi come le "allucinazioni" (generare informazioni plausibili ma errate) o la limitazione alle conoscenze acquisite durante il loro training.
È in questo contesto che gioca un ruolo importante la Retrieval-Augmented Generation (RAG) una tecnica innovativa che sta rivoluzionando il modo in cui interagiamo con gli LLM, rendendoli più precisi, affidabili e aggiornati. RAG rappresenta un approccio sempre più centrale per costruire sistemi conversazionali, assistenti intelligenti e motori di domanda-risposta capaci di combinare le potenzialità dei modelli linguistici con l’accesso a fonti esterne di conoscenza.
In questo articolo esploreremo in dettaglio cos'è la RAG, come funziona, perché è così rilevante, e in cosa si differenzia da tecniche come la ricerca semantica.
Cos'è la Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) è una tecnica che migliora le capacità dei modelli linguistici di generare risposte accurate e informate recuperando informazioni da una base di conoscenza esterna e autorevole prima di generare la risposta finale.
In pratica unisce due componenti fondamentali dell'elaborazione del linguaggio naturale:
- Retrieval (recupero): l'accesso a una base di conoscenza esterna (come documenti, database o articoli) rilevante rispetto a una query o a un prompt;
- Generation (generazione): la produzione di una risposta coerente e contestuale usando un modello linguistico (solitamente un LLM) alimentato dai risultati recuperati.
Invece di basarsi unicamente sulla conoscenza "memorizzata" nel modello durante la fase di training, la RAG cerca attivamente dati pertinenti da un corpus di documenti, database o web, e li utilizza come contesto aggiuntivo per guidare la generazione dell'LLM e migliorare l’accuratezza, l’aggiornamento e la capacità di risposta.
Come funziona la Retrieval-Augmented Generation?
Il processo di RAG può essere schematizzato in tre fasi principali:
- Indicizzazione - I dati esterni vengono trasformati in rappresentazioni numeriche (embedding). Questi embedding catturano il significato semantico dei contenuti e vengono archiviati in database vettoriali ottimizzati per la ricerca di similarità.
- Query Embedding - Quando l'utente inserisce una query o un prompt, l'input viene convertito in un vettore numerico (embedding) utilizzando lo stesso modello di encoding impiegato per i documenti.
- Document retrieval - L'embedding della query viene utilizzato per cercare, all'interno dell'indice vettoriale, i documenti o i frammenti di testo più semanticamente simili. Questo processo identifica rapidamente le informazioni più rilevanti rispetto alla richiesta dell'utente.
- Augmentation - frammenti di informazione recuperati vengono forniti al Large Language Model come contesto aggiuntivo insieme alla query originale dell'utente
- Generazione condizionata - L'LLM, ora arricchito da queste informazioni specifiche e aggiornate, utilizza sia le sue conoscenze interne che il contesto fornito per generare una risposta più accurata, pertinente e priva di allucinazioni. In questa fase, l'LLM non solo riformula le informazioni recuperate, ma le sintetizza, le riorganizza e le adatta per formare una risposta coerente e naturale.
RAG e modelli linguistici di grandi dimensioni (LLM)
Gli LLM, come GPT-4 o Claude, possiedono una grande capacità di generalizzazione, nel comprendere il linguaggio naturale, nel riassumere, tradurre e generare testo ma sono limitati dalla finestra temporale del training e dalla quantità di token che possono memorizzare. In pratica la loro conoscenza è limitata al corpus di dati su cui sono stati addestrati, che può essere obsoleto e non specifico per un determinato dominio.
Con l’approccio RAG, si supera questo limite:
- Si può accedere a informazioni aggiornate in tempo reale (come articoli di cronaca, database aziendali, documenti interni cioè a tutti quei dati o informazioni che non erano presenti nei dati di training;
- Si evitano o almeno si riducono le allucinazioni, cioè affermazioni scorrette o inventate;
- Si riduce il rischio di bias legati ai dati di training.
- Consente agli LLM di rispondere a domande specifiche su un dominio (ad esempio, la documentazione interna di un'azienda) senza dover essere riaddestrati su quel corpus di dati.
- Le risposte generate possono spesso includere riferimenti alle fonti da cui le informazioni sono state recuperate, aumentando la fiducia e la trasparenza.
In breve, RAG estende la memoria dei LLM e li rende strumenti di ricerca e generazione più affidabili e personalizzabili.
Qual è la differenza tra Retrieval-Augmented Generation e ricerca semantica?
Entrambe le tecniche si basano sul recupero semantico di contenuti, ma perseguono obiettivi diversi:
| Caratteristica | Ricerca semantica | Retrieval-Augmented Generation |
|---|---|---|
| Output | Lista di documenti o frammenti | Risposta generata in linguaggio naturale |
| Modello di generazione | Assente | Presente (es. LLM come GPT, BART) |
| Finalità | Navigazione e lettura da parte dell’utente | Risposta autonoma ed elaborata del sistema |
| Personalizzazione | Limitata | Alta: si può ottimizzare su dominio o contesto |
La ricerca semantica punta a trovare i documenti più rilevanti per una query considerando il significato, RAG invece non si limita a restituire risultati: li sintetizza e li contestualizza, offrendo un’esperienza più simile al dialogo con un esperto.
Perché utilizzare la RAG e perché è così importante?
L’importanza della Retrieval-Augmented Generation deriva da cinque fattori principali:
- Contesto aggiornato
È possibile fornire risposte basate su contenuti aggiornati senza riaddestrare il modello. - Fonte Verificabile
I contenuti generati possono essere tracciabili: ogni risposta è ancorata a documenti reali, consultabili. - Riduzione delle Allucinazioni
Il contesto esterno "ancora" l’LLM alla realtà. - Domini specifici e personalizzati
RAG permette di integrare basi di conoscenza aziendali, scientifiche o verticali in modo flessibile. - Costo-Efficienza:
Più economico del fine-tuning per aggiornare conoscenze.
È quindi una soluzione ideale per casi in cui serve precisione, aggiornamento continuo e accountability.
Alcuni campi di applicazione
La RAG sta già trasformando il modo in cui interagiamo con l'AI in diversi settori, ad esempio:
- Medicina: Diagnosi assistita recuperando da database di ricerche cliniche.
- Legale: Analisi di contratti con riferimento a leggi attuali.
- Ricerca Accademica: Q&A su papers scientifici.
- Supporto IT: Assistenti che risolvono problemi tecnici basandosi su documentazione interna, forum e knowledge base aziendali.
Utilizzare la RAG nelle applicazioni di chat
Sempre più sistemi di chatbot avanzati, come gli assistenti virtuali in ambito legale, medico o customer care, adottano l’architettura RAG per garantire:
- Risposte puntuali basate su manuali tecnici o regolamenti o eventi recenti;
- Personalizzazione della conversazione su base utente o aziendale;
- Aggiornabilità dei contenuti senza modificare il modello.
In pratica, la RAG trasforma una chat generica in un agente intelligente specializzato.
Quali sono i vantaggi della Retrieval-Augmented Generation?
Ecco un riepilogo dei principali vantaggi della RAG:
- Accesso a conoscenze esterne e aggiornate
- Riduzione delle allucinazioni tipiche dei LLM standalone
- Flessibilità e scalabilità su basi dati diverse
- Tracciabilità delle fonti
- Maggiore controllo sulla qualità delle risposte
- Perfetta integrazione con architetture esistenti (es. API, knowledge base)
La RAG rappresenta un salto evolutivo per gli LLM, trasformandoli da "enciclopedie statiche" a sistemi dinamici capaci di apprendere contestualmente. Con la sua capacità di fondere recupero intelligente e generazione avanzata, è destinata a diventare uno standard per applicazioni enterprise e consumer dove accuratezza e aggiornamento sono critici.
ARTICOLI CORRELATI
Energia pulita per il nostro cloud ![]() Low CO2
Low CO2





Openapi SpA Unipersonale - Società sottoposta a direzione e controllo della Open Holding Srl - Viale Filippo Tommaso Marinetti 221 - 00143 Roma - REA 1378273 Cap. Soc. € 50.000,00 i.v. – P.I. IT12485671007 - CODICE DESTINATARIO 'USAL8PV' - PEC: 
Openapi è certificata: Sistema qualità UNI EN ISO 9001:2015 - Qualità dei Dati ISO 25012:2014 - Gestione della Sicurezza ISO/IEC 27001:2022 - Parità di Genere UNI PdR 125:2022
Tutti i prezzi sono da considerarsi al netto di eventuale IVA, eventuali imposte di bollo, diritti di segreteria e/o imposte o tasse altrimenti denominate se dovute. Tutti i loghi elencati nel portale sono coperti da copyright e di proprietà dei rispettivi proprietari.








